



VEL-O-DROME
I went to the Six Day at the Olympic Velodrome this week. Great atmosphere, lots of fun.
They've gone full Wipeout with it all. A DJ from Ministry of Sound watching the action and keeping tempo accordingly. Coloured flood lighting. Introducing all the riders one by one as they do laps. Very little hanging around between events, and you mostly knew what was going on.
And whoever had the Derny riders come out to Ride of the Valkyries deserves a bonus.



Hey Thermostat
Not a Nest

As I wrote before, I've been hacking around with my wireless thermostat. Over the weekend I spent a couple of hours throwing together some code to act as a thermostat control loop, running from a Raspberry Pi. I've shared the code on GitHub.
There's two bits: a little C executable using Wiring Pi, that sends the commands to the boiler, and a Go executable that watches the temperature from an attached digital thermometer (a DS18B20) and triggers the thing that sends the commands. (The whole thing was Go for a while, but Go is too unreliable for timing the transmission, so it seemed easiest to move that bit to Wiring Pi in C.)
To put all this on a schedule, I'm using cron to write the desired temperature into a file that's being read every few seconds. If the monitored temperature goes 0.5°C over the desired temperature, the boiler turns off. And if it goes 0.5°C under, it turns on. It's a simple little system, but it's been running for a couple of days now, and hasn't set the house on fire yet.
The thermostat is now marginally less convenient than it was when I started, so the next step is to do what I promised with a shared calendar (not everyone in the family wants to SSH in to turn the heating on).
And it's not done until you've put it in a nice box and it doesn't look like an improvised explosive device. I've always enjoyed watching Tom put things in boxes, so it might be time to get some advice.
For a stretch goal, I'd like to poke around with HomeKit integration: "Hey Siri, turn the heating on", etc. And actually, thinking about it, that's something you can't do with a Nest.
Electric Motors

For Matt, from The Secret Life of the Home at the Science Museum. More about the making of the exhibition.
Reverse engineering a wireless thermostat
We moved the boiler in our house a few months ago, and replaced the wired, rotary thermostat in the process, with a 7 day digital wireless one. Or rather, the builders did, and I didn't really pay attention.
The timers are pretty simple - a morning schedule, an early evening schedule and a late evening schedule - but we're often in and out at different times, and the UI is so terrible and the buttons so horrible to press, it's preferable to just sit in the cold and shiver.
Anyway, I wanted to see if I could control the heating from something smarter. I've not quite done that yet, but I've managed to reverse engineer the signalling, and I thought it might be useful to write down how I did it.
We've got a Tower RFWRT thermostat - it's pretty cheap. There's two parts: the heating control unit, connected to the boiler, and a wireless thermostat you can place anywhere within range. These communicate over 433MHz, an unlicensed band which is pretty common for household devices.
The thermostat sends one of two command: turn on or turn off. It sends the current command on a 30s cycle, and when the state is changed. If the on command isn't received for a certain period (the thermostat has gone out of range, run out of battery, etc.) the heating control unit will switch the boiler off as a safety measure.
If we can find out what these signals are we can send them ourselves, and eventually replace the wireless thermostat with something smarter. (Or, y'know, you can just buy a Nest or something. You can stop reading here.)
There's a few ways to receive 433MHz signals, but the easiest for me was to use an RTL-SDR USB digital TV receiver. These are about £10, and let you listen across a wide range of frequencies (not just TV/radio), up to about 1700MHz.
I used CubicSDR, a Mac SDR application, and pressed the temperature controls up and down watching for the on/off commands. Sure enough, I spotted a short blip whenever the desired temperature is set.
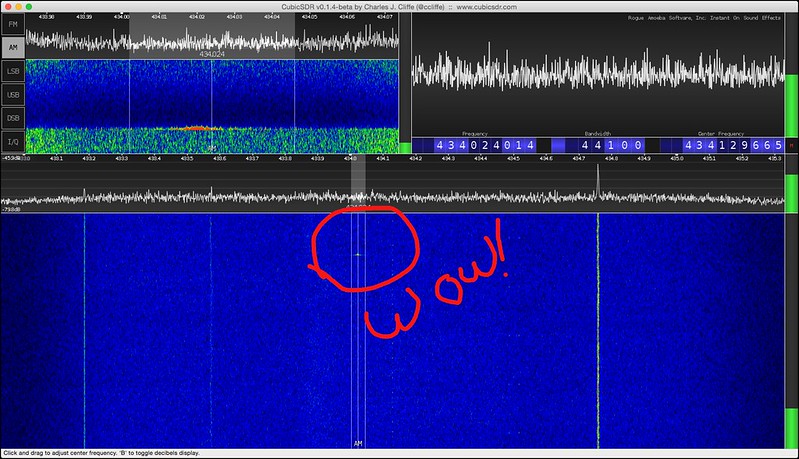
Using Audio Hijack (Soundflower works too), I recorded both commands to an audio file, trimmed the silence, and put the two segments side by side to compare.
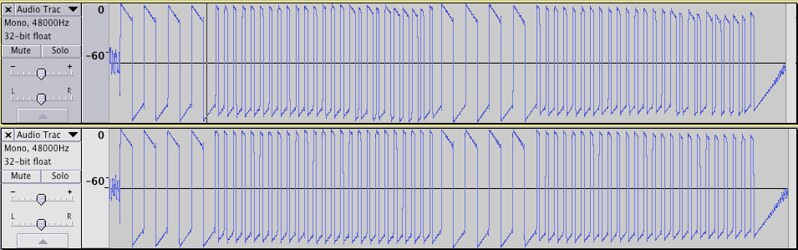
It looks like the signal is repeated twice, probably to reduce the likelihood of interference.
You can see a preamble at the beginning - a long high and long low, four times - probably designed to let the receiver calibrate its automatic gain control. These receivers crank up the volume (and the noise) during silence, and then adjust it when they hear a signal. The preamble gives the gain control a chance to respond so the beginning of the data isn't lost in the noise.
After that we're into the command data. I spent a long time staring at this, initially thinking it was Manchester encoded, before realising I needed to switch Audacity into ‘Waveform (dB)’ mode to see what's really going on. This is actually pulse width modulation, with a 0 sent as a short high and a long low, and a 1 sent as a long high and a short low.
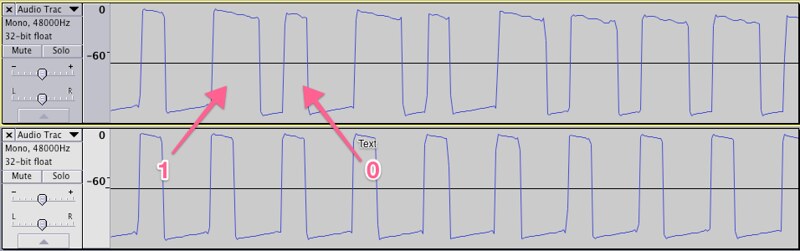
I measured each short section as 250μs long, and each long section as 500μs, and each preamble section as 1000μs.
The off command is just a run of 25 zeros, while the on command sends a few 1s too. It doesn't really matter what it means — I just need to send the same thing.
I took a cheap 433MHz transmitter and soldered a coiled 17cm antenna on. I attached this to the digital out of an Ardiuno, and wrote a little script to perform the transmission.
#define transmitPin 4 // Digital Pin 4
// on
bool data[] = { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 1, 1, 1, 0, 0 };
// off
// bool data[] = { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 };
int shortDelay = 250;
int longDelay = 500;
int preambleDelay = 1000;
void setup() {
Serial.begin(9600);
pinMode(transmitPin, OUTPUT);
delay(3000);
}
void loop() {
sendPreamble();
sendData();
sendPreamble();
sendData();
delay(30000);
}
void sendPreamble() {
for (int i = 0; i < 4; i++) {
digitalWrite(transmitPin, HIGH);
delayMicroseconds(preambleDelay);
digitalWrite(transmitPin, LOW);
delayMicroseconds(preambleDelay);
}
}
void sendData() {
for (int i = 0; i < sizeof(data); i++) {
bool b = data[i];
if (b == 1) {
digitalWrite(transmitPin, HIGH);
delayMicroseconds(longDelay);
digitalWrite(transmitPin, LOW);
delayMicroseconds(shortDelay);
} else {
digitalWrite(transmitPin, HIGH);
delayMicroseconds(shortDelay);
digitalWrite(transmitPin, LOW);
delayMicroseconds(longDelay);
}
}
}A little click, the boiler goes on, and we're in business. To start with, I'd like to schedule the timing from a shared family calendar, so now I need to make a thermostat control loop, and drive the whole thing from something web connected, like a Raspberry Pi.
CityCyclist 1.0

tldr; I made an app for bike navigation, you can download it here.
For a few months, in slivers of spare time, I’ve been working on a little app for city bike navigation, called CityCyclist.
I’ve tried to build something clean and accessible, that gets a good bike route on the screen as quickly as possible. That’s glanceable while on a bike, and more useful when off.
KEY INNOVATIONS!
There’s a little scrubber on the elevation profile at the bottom to fly quickly along a route without zooming and panning around. My hypothesis was that might make it easier to consign a route to memory. I suspect that’s not true, but I still like it.
The search results use a combination of Foursquare and Apple’s address geocoder, and seem fairly good.
The routing is powered by CycleStreets (backed by OpenStreetMap) with a selection of three options: fast, balanced, quiet. (UK only for now.)
END KEY INNOVATIONS!
I think version 1.0 is a good base for future experiments. I’d like to try a take on turn-by-turn navigation that works when the phone is in your pocket or bag, and I’d like to find a feedback loop to improve routing/map data. But this’ll do for now.
It’s in the App Store now and it’s free. If you give it a try, I’d love to know what you think. Get it here.
(PS: If you work for the kind of organisation that would benefit from me supporting, improving, and getting this app to as many people as possible, and want to help out, do get in touch.)
What Do People Do All Day?

One of Sam’s favourite books at bedtime is Richard Scarry’s ‘What Do People Do All Day?’. I was going to write a post all about it, because it’s kind of brilliant (explaining economic and industrial processes for the under fives! lovely drawings!) and kind of terrible (gender roles! a society seen solely through the eyes of capitalism!).
So I started writing, but then I found this great post deconstructing it better than I could:
Which rather begs my usual question: so why is it that we no longer make these kinds of books? Why is it that we have shifted our focus to how things work or how people used to work as opposed to how people work now? Is it that work is too elusive, that new economy jobs are harder to draw? Can we not deal with the fact that Alfalfa has become a derivatives trader? But work of course is far from invisible. It’s not just that we do so many of the occupations lovingly drawn by Scarry, and in more or less the same way. It’s also that people still work in manufacturing, only mostly elsewhere. We could teach our children about that, just like we teach them that everybody poops.
(Obviously, someone has done a ‘funny’ 21st century version, but that doesn’t count.)
So I read it, and I looked at the news, and it became pretty clear to me while I'd like to see more of this sort of book, the kids will be just fine. But we could do with a bit more Richard Scarry, and a bit more How Things Work, and a bit more Secret Life of Machines for everyone else.
New year, new job!

This is my last fortnight at Newspaper Club, after a brilliant five and a half years. We’ve built a great little company that’s growing fast, but it’s time for me to move on to something new. I’m pleased to be leaving it in very capable hands, and I can’t wait to see all the 2015 plans come to fruition. I’m going to miss all my colleagues there, but a special mention to Anne, who has worked tirelessly to turn our silly idea into, well, a non-silly idea. One that employs people, pays taxes and has happy customers all over the world.
This has been in the works for a little while, and I’d planned on going freelance again, until the next meaty long-term thing came along. So it was a surprise to find that thing before I’d even got started.
I’m joining Moo, as Head of Technology of a new multidisciplinary team working on scalable digital products. We’re starting from scratch, with the Moo engine behind us, and a blank whiteboard in front of us. Exciting! (Also, in an odd, but nice twist, we’ll be occupying the old RIG/BERG/MakieLab space on Scrutton St! Come visit!)
Happy 2015 everyone!
Sunrise, Mabley Green
It's that time of year again.



